Utility vs Understanding: the State of Machine Learning Entering 2022

The empirical utility of some fields of machine learning has rapidly outpaced our understanding of the underlying theory: the models are unreasonably effective, but we're not entirely sure why. Conversely, other areas of research that are relatively well understood are difficult to implement or have limited applicability in practice. This article attempts to map different fields of machine learning with respect to their utility and understanding, and explores how scientific and technological progress manifests within this framework.
Disclaimer
Constructing this matrix is a highly subjective exercise, that reduces multi-faceted fields to undefined, single values on one-dimensional scales, that themselves are comprised of multiple factors. This matrix represents my personal view - one in which fields are crudely assessed only by their general characteristics. I acknowledge the imprecision, disregard of nuance, and that I'm far from an expert on most of these techniques.
This article is primarily intended to discuss the contrast between empirical utility and theoretical understanding, and how they relate to scientific/technological progress. Precisely positioning fields of research within a matrix is not the objective.
By empirical utility, I mean a composite measure that considers a method's breadth of applicability, its ease of implementation, and most of all: how useful it is in the real world. Some methods with high utility have broader applicability whereas others are more powerful but only in narrow domains. Methods that are reliable, predictable, and without significant pitfalls are also deemed to have higher utility.
By theoretical understanding, I mean a composite measure that considers interpretability and explainability (i.e. how do inputs relate to outputs? How can I obtain a desired result? What are the internal mechanics of this technique?), and the depth and completeness of its literature.* Methods with low understanding typically employ heuristics or extensive trial and error when being implemented. Methods with high understanding tend to have formulaic implementations with strong theoretical underpinnings and predictable outcomes. Simpler methods (e.g. linear regression) have lower theoretical ceilings whereas more sophisticated methods (e.g. deep learning) have higher theoretical ceilings. When it comes to the depth and completeness of a field's literature, I've assessed the field against its hypothetical theoretical ceiling - an imagined quantity derived from intuition.
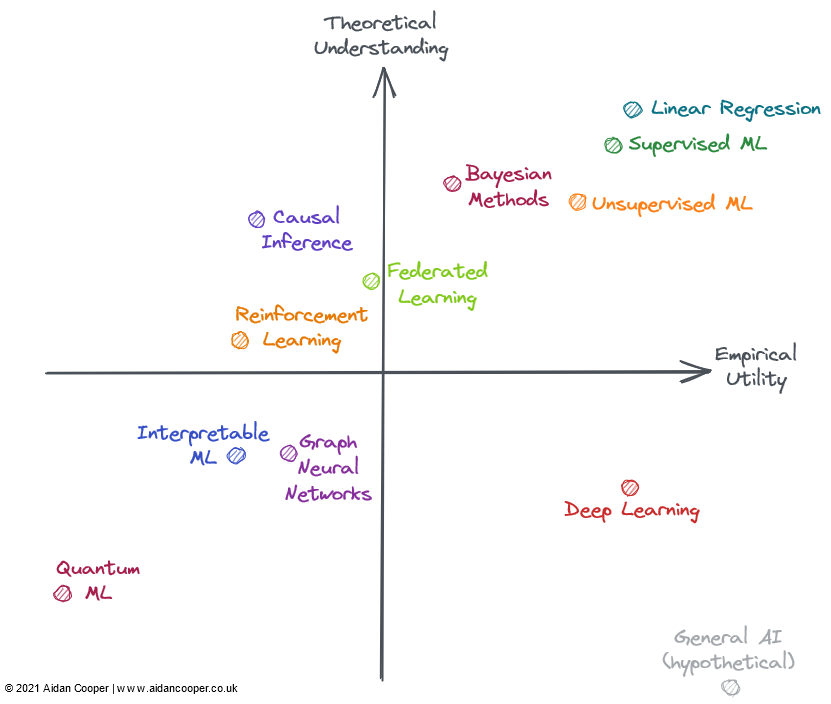
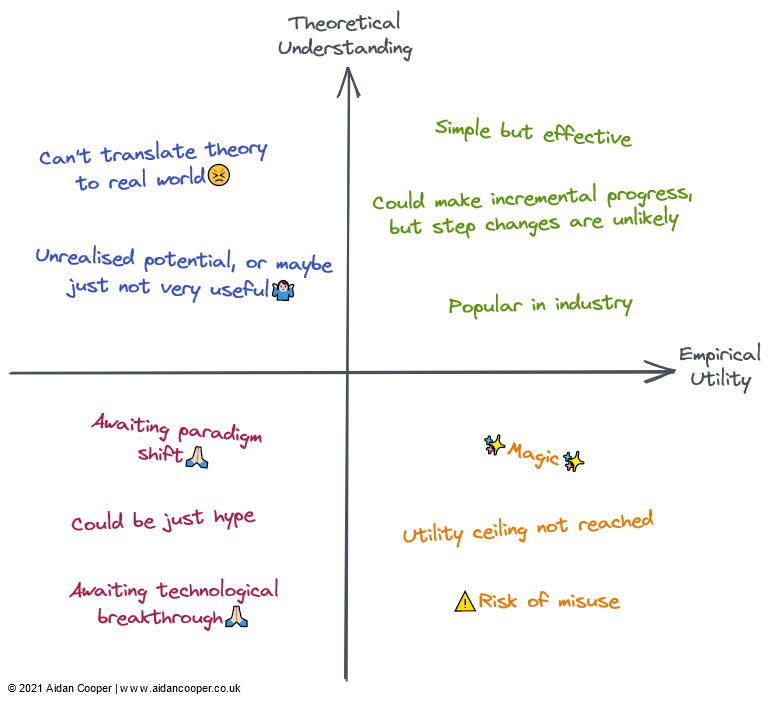
We can construct the matrix as four quadrants, with the intersection of the axes representing a hypothetical, semi-mature reference field that has both average understanding and average utility. This allows us to interpret fields within the matrix in qualitative terms, depending on the quadrant in which the field lies, as shown in Figure 2. Fields in a given quadrant are likely to possess some or all of these generalised characteristics.
Generally, we expect utility and understanding to be loosely correlated, as things that are well understood are more likely to be useful than those that aren't. This means that most fields should be in either the bottom left or top right quadrants. Fields that lie far from this diagonal represent interesting exceptions. Usually, utility lags behind theory, as it takes time for nascent research to be translated to real-world applications. As such, the diagonal should lie above the origin rather than directly through it.
Machine Learning Fields in 2022
Not all of these fields are entirely encompassed by machine learning (ML), but they can all be applied in the context of ML or have close ties to it. Many of the evaluated fields overlap and cannot be cleanly delineated: advanced approaches to reinforcement, federated, and graph ML are typically based on deep learning. In these instances, I've considered the fields in relation to the non-deep learning aspects of their theory and utility.
Top Right Quadrant: High Understanding, High Utility
Linear regression is the canonical example of a technique that is simple, well-understood, and highly effective. It is the underrated, unsung hero, often overlooked for its trendier peers. Its breadth of use and thorough theoretical basis not only places it in the top right quadrant, but anchors it in the top right corner.
Traditional (read: "not deep") machine learning has matured into a field of both high understanding and utility. Sophisticated ML algorithms, such as gradient boosting decision trees, have proven themselves to be generally superior to linear regression for non-trivial prediction tasks. This is unequivocally the case for big data problems. There are arguably still holes in the theoretical understanding of over-parameterised models, but implementing machine learning is a refined, methodological process, and models are reliably operationalised in industry settings (when done right). The additional complexity and flexibility, however, does result in erroneous implementations, which is why I've placed machine learning left of linear regression. Generally speaking, supervised machine learning is more refined and has been more impactful than its unsupervised counterpart, but both methods address different problem spaces effectively.
Bayesian methods have a cult following of ardent practitioners, who preach its superiority over more prevalent classical statistical approaches. There are situations where Bayesian models are particularly useful: when point estimates alone are insufficient, and estimates of uncertainty are important; when data is limited or has high levels of missingness; and when you have knowledge of the data generating process that you want to explicitly imbue in the model. The utility of Bayesian models is limited by the fact that for many problems, point estimates are good enough, and people just default to non-Bayesian approaches. Whatsmore, there are ways of quantifying uncertainty for conventional ML (they're just rarely used). Usually, it's easier to simply fit ML algorithms to data, rather than have to think about data generation mechanisms and priors. Bayesian models are also expensive computationally and would have higher utility if theoretical advancements produced better sampling and approximation methods.
Bottom Right Quadrant: Low Understanding, High Utility
Contrary to how most fields progress, deep learning has achieved some spectacular successes despite the theoretical side proving to be fundamentally difficult to progress. Deep learning exemplifies many of the traits of a poorly understood method: models are unstable, difficult to build reliably, configured based on weak heuristics, and yield unpredictable results. Dubious practices such as random seed "tuning" are surprisingly common, and the mechanics of working models are hard to explain. And yet deep learning continues to advance and achieve superhuman levels of performance in areas such as computer vision and natural language processing, opening up a world of otherwise impenetrable tasks such as autonomous driving.
Hypothetically, General AI would occupy the bottom right corner, as, by definition, superintelligence is beyond human comprehension and could be utilised for any problem. For now, it's included only as a thought experiment.
Top Left Quadrant: High Understanding, Low Utility
Causal inference in most forms isn't machine learning, but sometimes is, and is always of interest for predictive models. Causality can be dichotomised into randomised controlled trials (RCTs) versus more sophisticated causal inference methods that attempt to measure causal effects from observational data. RCTs are theoretically simple and give rigorous results, but are usually expensive and impractical - if not impossible - to conduct in the real world, so have limited utility. Causal inference methods essentially mimic RCTs without the burden of having to do one, making them much less prohibitive to perform, but have many limitations and pitfalls that can invalidate results. Overall, causality remains a frustrating pursuit, in which current methods are often unsatisfactory the questions we want to ask, unless the questions can be explored via RCTs or they happen to fit nicely to certain frameworks (e.g. as a serendipitous consequence of "natural experiments").
Federated learning (FL) is a cool concept that receives surprisingly little attention - probably because its most compelling applications require distribution to vast numbers of smartphone devices, such that FL is only really investigable for two players: Apple and Google. Other use cases exist for FL, such as pooling proprietary datasets, but there are political and logistical challenges to coordinating these sorts of initiatives, limiting their utility in practice. Nonetheless, for what sounds like an exotic concept (loosely summarised as: "bring the model to the data, not the data to the model"), FL is effective and has tangible success stories in areas such as keyboard text prediction and personalised news recommendations. The fundamental theory and technology behind FL seem robust enough for FL to be utilised more broadly.
Reinforcement learning (RL) has attained unprecedented levels of competence in games such as chess, go, poker, and DotA. But outside of video games and simulated environments, RL hasn't translated convincingly to real-world applications. Robotics was meant to be RL's next frontier, but this hasn't come to fruition - reality appears to be much more challenging than highly constrained toy environments. That said, RLs achievements so far are inspiring, and people who really like chess might argue its utility deserves to be higher. I'd like to see RL realise some of its potential real-world applications before placing it towards the right of the matrix.
Bottom Left Quadrant: Low Understanding, Low Utility
Graph neural networks (GNNs) are an extremely hot field of ML right now, with promising results across multiple domains. But for many of these examples, it's unclear if GNNs are better than alternative approaches that use more conventionally-structured data paired with deep learning architectures. Problems in which the data is naturally graph-structured, such as molecules in cheminformatics, seem to have more compelling GNN results (although even these are often inferior to non-graph related methods). More so than most fields, there seems to be a large disparity between open source tools for training GNNs at scale versus in-house tools used in industry, limiting the viability of large GNNs outside of these walled gardens. The complexity and breadth of the field suggest a high theoretical ceiling, so there should be room for GNNs to mature and convincingly demonstrate superiority for certain tasks, which would lead to greater utility. GNNs could also benefit from technological advancements, as graphs currently don't lend themselves naturally to existing computing hardware.
Interpretable machine learning (IML) is an important and promising field that continues to gain traction. Techniques such as SHAP and LIME have emerged as genuinely useful tools for interrogating ML models. However, the utility of existing approaches hasn't been fully realised due to limited adoption - robust best practices and implementation guidelines haven't been established yet. The current major weakness of IML, however, is that it doesn't address the causal questions that we're truly interested in. IML explains how models make predictions, but not how the underlying data causally relates to them (despite often being erroneously interpreted as such). Until significant theoretical progress is made, legitimate uses of IML are mostly limited to model debugging/monitoring and hypothesis generation.
Quantum machine learning (QML) is well outside my wheelhouse, but currently seems to be a hypothetical exercise, patiently waiting for viable quantum computers to become available. Until then, QML trivially sits in the bottom left corner.
Incremental progress, technological leaps, and paradigm shifts
There are three main mechanisms by which fields can traverse the theoretical understanding vs empirical utility matrix (Figure 3).
Incremental progress is the slow and steady advance that inches fields up and towards the right of the matrix. The past few decades of supervised machine learning is a good example of this, during which time increasingly effective predictive algorithms were refined and adopted to give us the powerful toolbox we enjoy today.† Incremental progress is the status quo for all maturing fields, outside of times when they undergo more drastic movements due to technological leaps and paradigm shifts.
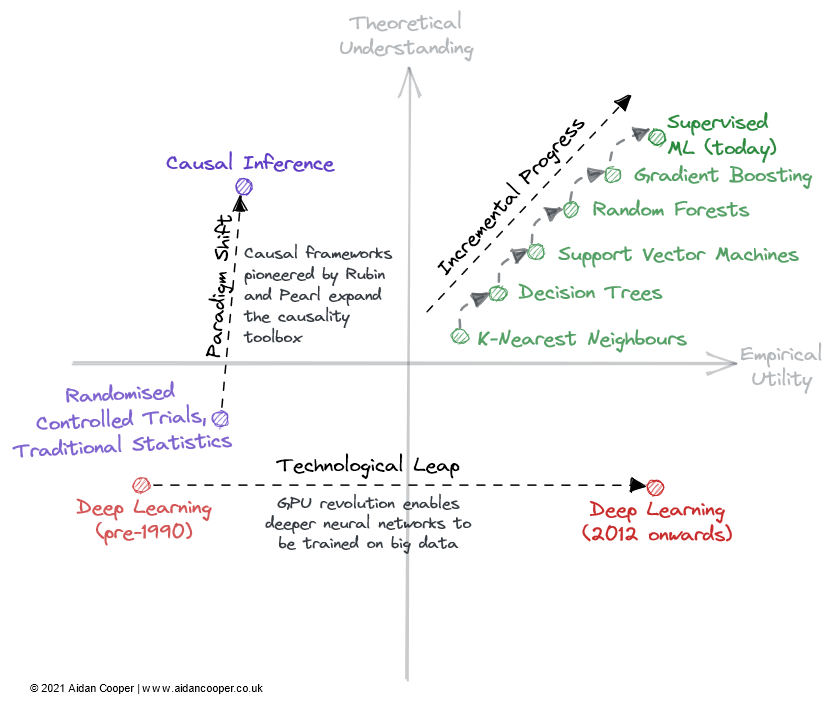
Some fields see step changes in scientific progress due to technological leaps. The field of deep learning wasn't unlocked by its theoretical underpinnings, which were discovered over twenty years before the deep learning boom of the 2010s - it was parallel processing enabled by consumer GPUs that spurred its resurgence. Technological leaps usually manifest as rightward jumps along the empirical utility axis. Not all technologically-led progression is a leap, however. Deep learning today is characterised by incremental advancements achieved by training larger and larger models using more computing power and increasingly specialised hardware.
The final mechanism for scientific progress within this framework is the paradigm shift. As identified by Thomas Kuhn in his book, The Structure of Scientific Revolutions, a paradigm shift represents an important change in the basic concepts and experimental practices of a scientific discipline. The causal frameworks pioneered by Donald Rubin and Judea Pearl are one such example, that elevated the field of causality from randomised controlled trials and traditional statistical analysis to a more powerful, mathematised discipline in the form of causal inference. Paradigm shifts usually manifest as upward movements in understanding, that may be followed or accompanied by an increase in utility.
However, paradigm shifts can traverse the matrix in any direction. When neural networks (and subsequently, deep neural networks) established themselves as a separate paradigm to traditional ML, this initially corresponded to a decrease in both utility and understanding. Many nascent fields branch off of more mature research areas in this manner.
Predictions, and deep learning's scientific revolution
To conclude, here are some speculative predictions for what I think the future may hold (Table 1). Fields in the top right quadrant are omitted, as they're too mature to see significant progress.
| Field of Research | Predictions for 2022 onwards |
|---|---|
| Deep Learning | Deep learning will continue to see incremental progress from scaling increasingly large models, without notable advancements to the underlying theory. I have no idea if this will be accompanied (separately) by a paradigm shift-level scientific breakthrough during 2022, but let's hope so! |
| Causal Inference | Studying causality in the real world outside of controlled causal frameworks will continue to be challenging and fraught with pitfalls. It's still unobvious if and how ML could learn and discover causal relationships. I think this is an inherently difficult problem that won't be solved soon, neither theoretically nor in practice. |
| Federated Learning | Federated learning will continue to mature and find further uses on smartphone devices (led by Apple), supported by advancements in on-device AI chipsets. I expect there'll be incremental progress in 2022 as the utility of federated learning on smartphones catches up with the potential of the existing theory. This may eventually be accelerated by regulatory pressure or consumer concerns around data privacy, although I don't expect these to be huge drivers in 2022. |
| Reinforcement Learning | Optimistically: in 2022, DeepMind will make a notable advancement in applying deep reinforcement learning to a real-world problem, that will shift reinforcement learning into the top right quadrant. Imitation learning will become an increasingly common starting point for training reinforcement learning models. |
| Graph Neural Networks | I think GNNs will prove more successful for modelling graph representations (e.g. molecules, and other naturally graph-structured data) than node representations. In 2022, I think we'll see more examples of graph neural networks outperforming alternative methods for problems related to chemical structures. I predict modest progress for both understanding and utility, but only in narrow domains (other deep learning approaches will prove superior for most tasks). |
| Interpretable ML | In 2022, the existing techniques for interpretable ML will see broader adoption within industry. SHAP will establish itself as the de facto starting point (if it hasn't already). Neural networks will still be difficult to grok. Most of the progress will be seen along the utility axis, as standardised best practices emerge. |
| Quantum ML | Quantum ML won't progress until quantum computing achieves a technological leap, which won't happen in 2022. Expect no movement. |
| ✨General AI✨ | Let's not get carried away... |
Table 1. Predictions for how select fields of machine learning may or may not progress in the future
A more important observation than how individual fields will progress, however, is the general trend towards empiricism, and an increasing willingness to concede comprehensive theoretical understanding.
Historically, theory (hypotheses) came first, before ideas were enacted. Deep learning has spearheaded a new scientific process that flips this on its head. Methods are expected to demonstrate state of the art performance before people pay attention to the theory. Empirical results are king and theory is optional.
This has led to widespread gaming of the system in ML research, whereby new state of the art results are attained by trivially modifying existing methods and relying on stochasticity to beat baselines, rather than meaningfully advancing the theory of the field. But perhaps this is the price we pay for this new wave of machine learning prosperity.
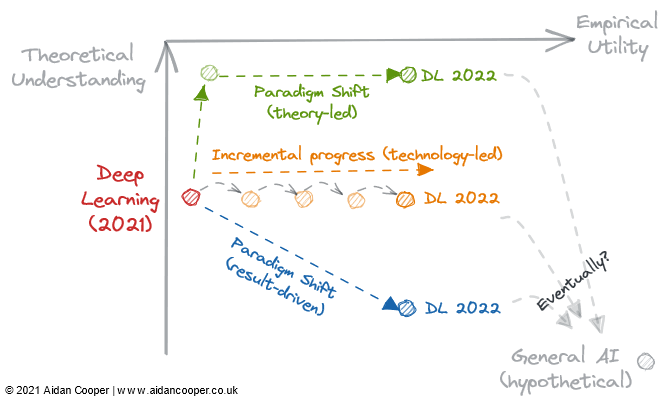
2022 could prove to be the tipping point for whether deep learning irreversibly adopts this new results-led process and relegates theoretical understanding to being an optional extra. These are the questions we should be pondering (Figure 4):
- Will a theoretical breakthrough allow our understanding to catch up with the utility, and transform deep learning into a more methodical discipline, like traditional machine learning?
- Is the existing deep learning literature adequate for utility to increase indefinitely, simply by scaling larger and larger models?
- Or will an empirical breakthrough lead us further down the rabbit hole, into a new paradigm of enhanced utility, albeit one that we understand even less?
- Do any of these routes lead to general AI?
See you in 2023.
* There is no consensus definition for the terms 'interpretability' and 'explainability' within machine learning, and many researchers use them interchangeably
† The emergence of, e.g. the random forest algorithm, doesn't increase the understanding or utility of the SVM algorithms that preceded it, but it does advance the overarching field of supervised ML
Member discussion